|
John writes ...  I have worked directly or indirectly on DNA and genes from my PhD student days and throughout my research career. My focus was at the interface of biochemistry and genetics, an area of science that we call Molecular Biology and with which I am very familiar. It is replete with marvellous molecules and mechanisms, although, for those of us who are practitioners, it is too easy to take those marvels for granted. We need to ‘stand and stare’ perhaps for just a few minutes to remind ourselves that the whole topic is amazing. Let me start with the genetic material itself, DNA. DNA molecules are not really complex, although they can be very long (long in relation the dimensions of living cells). DNA molecules are polymers, that is they are built of many individual components linked together. These individual components are called bases in biochemical shorthand and there are only four sorts – as I said, DNA is not a complex molecule – and they can occur in any order. This simplicity fooled scientists for a long time: how could such a simple molecule carry genetic information? DNA was discovered in 1869 and was shown to be present in chromosomes early in the 20th century but it was not until the end of World War II that this key role of DNA was finally demonstrated beyond doubt. And of course, that demonstration led to extensive further research, including the elucidation of its structure by Watson and Crick – and others – in 1953. All the information required for the development and second-by-second life of all organisms is encoded just in the four bases of DNA, the specific information coming from the order and the number of bases in subsections of DNA molecules that we call genes. Further – and this fact still fills me with amazement – all living organisms on Earth read the code in the same way. Every living organism is related to every other, consistent with the idea that there was just one origin of life (abiogenesis) and all life-forms are derived from that common beginning. 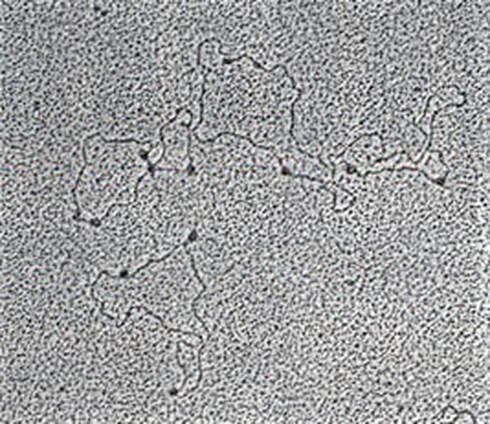 Caption for image: In bacteria, the DNA molecules are circular and, in addition to their main DNA molecule, they often have mini-circles that carry just a few genes. We constructed artificial mini-circles by splicing different pieces of DNA together in order to study the interaction of a particular protein (see below) with particular structures in DNA. The interaction is seen here under an electron microscope. Image copyright © Sara Burton, John Bryant and Jack Van’t Hof.  But there is more. The information in DNA must be passed on. Every new cell needs a faithful copy of the genetic information from its ‘parent’. This is where the famous ‘double helix’ comes in (if you are not sure what a helix is, think of a ‘spiral’ staircase. A spiral staircase is actually not a spiral but a helix). A molecule of DNA consists of two helices wound round each other and which are held together because of specific abilities of the bases to form pairs with each other. Using just the initials of the bases to indicate their names, A in one helix can only pair with T in the other; similarly, G can only pair with C. I’m sure you can see that this immediately provides the means of passing on the code faithfully. If the two helices separate, then each single helix directs the synthesis of a new partner helix. For example, a T in the pre-existing single helix dictates that there must be an A at that position in the new helix. The structure of DNA means that it can direct its own faithful copying. That is both awesome and beautiful in its simplicity. If a human engineer had come up with this, we would say that he or she was a genius. As a Christian I say that the genius here is God. Thus the genetic code is safely passed on from generation to generation, but what does the code actually do? Well, it directs the synthesis of proteins, the cell’s working molecules. There are thousands of different sorts, many of which are enzymes – proteins that carry out biochemical reactions. Proteins are polymers (see above) built with amino acids, of which there are 20 types that vary significantly from each other in shape and size. The shape of a protein, essential for its function, depends on the particular array of amino acids – overall number and the order of different types within the molecule. Some proteins are small and quite simple, others are very large (in molecular terms). A code based on just four bases (read in groups of three) in DNA tells the cell the order in which to put the amino acids in a protein.
How does this happen? How is the code translated? The answer is not ‘Google Translate’ as one school student suggested to me! I’d like you to envisage the code as a row of beads of four different colours and the cell’s pool of amino acids as a pile of LEGO (TM) bricks of several different shapes and sizes. Those bricks do not fit onto the beads. In the same way, an individual amino acid cannot on its own recognise three bases and line up with them. The answer to this conundrum is in the form of adapter molecules which can recognise an individual amino acid and the three-base code that specifies that acid. These adaptor molecules ensure that the amino acids are built into proteins in the right order. It is an amazing mechanism and we have no understanding of how it evolved. This leads back to a point that I made at the beginning of this article. In Chapter 5 of the book, I wrote ‘… I cannot help think that we biologists are so used to this that we have become a little blasé.’ When we pause to think a little more deeply we can only react with awe and wonder at God’s magnificent creation. Note: I wrote a revised version of this blog for the Faraday Institute’s Faraday Churches web page. You can find it here, with a brief introductory paragraph from Ruth Bancewicz. John Bryant Topsham, Devon September 2021
0 Comments
Leave a Reply. |
AuthorsJohn Bryant and Graham Swinerd comment on biology, physics and faith. Archives
July 2024
Categories |
 RSS Feed
RSS Feed
